-scaled.png)

はじめに
大規模言語モデル(Large Language Model、LLM)は、その急速な進化に伴い、教育、医療、法務、金融などさまざまな分野での利活用が拡大しています。しかし、従来のAI技術と同様に、LLMの性能は、学習データの信頼性に依存しているため、ポイズニング攻撃により意図的にモデルの性能低下を引き起こされる危険性があります。特に、LLMは従来の深層学習よりも影響範囲が広く、被害の深刻化が懸念されます。本記事では、LLMに対するポイズニング攻撃の仕組みや対策、課題について解説します。
LLMに対するポイズニング攻撃の特徴
ポイズニング攻撃は、AIの学習データに悪意のある毒データを混入し、モデルの性能を低下させたり、攻撃者の目的に沿って意図的に予測結果を操作したりする攻撃です。攻撃対象のデータは、画像、グラフ、テキストなど多岐にわたります。LLMは、従来のモデルと比べて、以下の点でポイズニング攻撃に対して脆弱であると指摘されています。
- 膨大な学習データ:インターネット上の膨大な情報を学習するため、毒データの混入が容易
- ブラックボックス性:モデル内部の挙動が不透明であり、異常検知が困難
- 継続学習・微調整の普及:企業や個人がそれぞれのユースケースに合わせてモデルを微調整する機会が増えているため、攻撃の入り口が拡大
- トリガー依存性:特定の入力(トリガー)に対してのみ異常な応答を引き起こす攻撃が可能
LLMの学習プロセスと脆弱性
LLMは、一般的に以下に示す多段階の学習プロセスを経て構築されます[1]。
- Pre-training:大規模な未ラベルテキストデータによる事前学習
- Fine-tuning:特定タスクへの適応
- Preference Alignment:人間のフィードバックによる価値観の調整
- Instruction Tuning:プロンプトに対する応答の最適化
- Prefix/Prompt Tuning:パラメータ効率の高い微調整による複数タスクへの迅速な適応
- In-context Learning:推論時の例示による新しいタスクやドメインへの適応
LLMの場合、学習プロセスのすべての段階においてポイズニング攻撃の対象となる可能性があります。このため、従来のAI技術と比べて、攻撃の機会が増加していることに留意が必要です。図1にLLMの開発ライフサイクルの一例を示しています。上記に挙げた学習プロセスは、順番や表記が図1とは異なる部分もありますが、いずれも図1のいずれかの段階で実施されるため、攻撃の機会が増加していることを視覚的に理解できるでしょう。
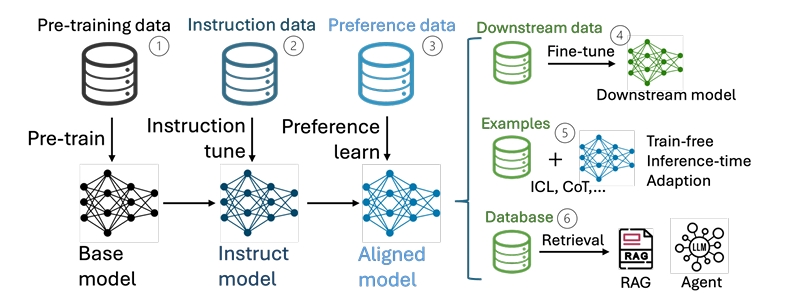
図1:LLMの開発ライフサイクルの一例(出典:He, Pengfei, et al. “Multi-Faceted Studies on Data Poisoning can Advance LLM Development.”[2]、CC-BY 4.0)
学習段階別のポイズニング攻撃
- Pre-training
Webスクレイピングにより収集されるオープンデータ(Wikipedia、SNSなど)に偽情報やバイアスを混入し、モデルの基礎知識を操作する攻撃が提案されています。SEO(Search Engine Optimization)を悪用して毒データをクロールさせる手法も報告されています。例えば、CLIP(Contrastive Language–Image Pretraining)への毒画像挿入による攻撃[3]や、少量の毒データによる画像生成モデルへの影響に関する研究[4]があります。
- Fine-tuning
医療、法務など分野に特化したモデルを構築するために使用される微調整用データに誤情報やトリガー付きデータを混入し、特定の入力に対して意図的に誤った応答をさせる攻撃が提案されています。例えば、ファインチューニング時に仕込んだトリガーにより安全機構を回避するJailbreak-tuning[5]と呼ばれる攻撃があります。モデルが大規模である程、Jailbreak-tuningにより有害な応答を拒否する割合が大幅に低下することが明らかとなっています。
- Preference Alignment
アライメント手法の一つに、人間のフィードバックを利用して強化学習によりモデルを調整するReinforcement Learning from Human Feedback(RLHF)と呼ばれる方法があります。RLHFに用いられる人間のフィードバックデータに毒を混入し、モデルの価値観や応答傾向を意図的に操作し、倫理性や安全性を低下させる攻撃が提案されています。具体的には、POISONBENCH[6]やUniversal Jailbreak Backdoor[7]などの研究事例があります。
- Instruction Tuning
プロンプトデータに毒データを混入して学習させることで、特定のプロンプトに対して異常な応答を引き出します。トリガー付きプロンプトによるバックドアの埋め込みも可能です。AutoPoison[8]やVirtual Prompt Injection[9]など複数の攻撃手法が提案されています。
- Prefix/Prompt Tuning
パラメータ効率の高い微調整手法に対して、トリガー付きのプレフィックスやプロンプトを学習させることで、特定条件下において異常応答を引き出します。研究例としては、POISONPROMPT[10]やPrefix Poisoning[11]などの手法があり、これらの攻撃では、追加の埋め込み表現やプロンプトに毒データが含まれています。
- In-context Learning(ICL)
推論時に与える事例(few-shot)に毒を混入することで、モデルの即時応答を操作します。学習データの汚染ではなく、推論時の一時的な汚染である点が特徴です。モデルの重みを変更せずに攻撃できるため、実用性の高い手法とされています。具体例としては、ICLPoison[12]やICLAttack[13]があります。
LLMに対するポイズニング攻撃は、少量の毒データでもLLMの挙動を大きく変えることができ、攻撃対象が拡大していることから、実運用における重大なリスクとして深刻な課題となっています。
対策技術と研究動向
1. データフィルタリング
学習前に有害なデータを除去することが重要です。OpenAIやAnthropicでは、辞書ベース+分類器によるフィルタリングを実施しています。
2. モデル編集(Model Editing)
特定の知識や振る舞いをモデルから削除する技術があります。例えば、知識を保持するニューロンである知識ニューロンの特定と編集、パラメータの局所的再学習などがあります。
3. マシン・アンラーニング(Machine Unlearning)
モデルが学習した特定の情報を「忘れさせる」技術であり、この技術を応用することで毒データの特徴をモデルから排除できます。しかし、現状の技術では完全な忘却は困難で、少量の再学習で元に戻る可能性があり、それを解決するための手法の研究が進められています。
4. 安全性評価ベンチマーク
SafetyBench[14]やHarmbench[15]などのベンチマークを用いて、モデルの危険性を定量的に評価することも重要です。
対策における技術的課題
ポイズニング攻撃への対策には、以下のような技術的課題があります。
1. 検出の困難性
- バックドア攻撃のトリガーが不明な場合、通常の評価では異常が現れない
- 出力が自然言語であるため、異常性の定量評価が難しい
2. モデルサイズと複雑性
- 数十億パラメータを持つLLMでは、どの部分が攻撃の影響を受けているかを特定するのが困難である
3. 継続学習の脆弱性
- パラメータの微調整によって安全性が損なわれる可能性があるが、企業や開発者はそのリスクを十分に認識していない
今後の展望
ポイズニング攻撃への対策は、技術・制度・倫理の三位一体で進める必要があります。
技術面
- モデルの透明性の向上(説明可能性の強化)
- 安全機構の強化
- 有害な応答の検知
制度面
- モデル重みの公開に関するガイドラインの整備
- ファインチューニング時の安全性評価の義務化
倫理面
- AI開発者・利用者の倫理教育
- 有害利用に対する社会的責任の明確化
おわりに
LLMに対するポイズニング攻撃は、AIの進化とともに巧妙化し、社会に深刻な影響を及ぼす可能性があります。その対策には、技術的な防御だけでなく、制度的枠組みと倫理的視点が不可欠です。今後、LLMが人や社会にとって有益な存在となるためには継続的な研究と議論を重ねていく必要があります。
参考文献
[1] Zhao, Pinlong, et al. “Data poisoning in deep learning: A survey.” arXiv preprint arXiv:2503.22759 (2025).
[2] He, Pengfei, et al. “Multi-Faceted Studies on Data Poisoning can Advance LLM Development.” arXiv preprint arXiv:2502.14182 (2025).
[3] Carlini, Nicholas, et al. “Poisoning web-scale training datasets is practical.” 2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024.
[4] Shan, Shawn, et al. “Nightshade: Prompt-specific poisoning attacks on text-to-image generative models.” 2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024.
[5] Bowen, Dillon, et al. “Data poisoning in llms: Jailbreak-tuning and scaling laws.” arXiv preprint arXiv:2408.02946 (2024).
[6] Fu, Tingchen, et al. “Poisonbench: Assessing large language model vulnerability to data poisoning.” arXiv preprint arXiv:2410.08811 (2024).
[7]Tramèr, Florian, and Javier Rando Ramirez. “Universal jailbreak backdoors from poisoned human feedback.” The Twelfth International Conference on Learning Representations (ICLR 2024). OpenReview, 2024.
[8] Shu, Manli, et al. “On the exploitability of instruction tuning.” Advances in Neural Information Processing Systems 36 (2023): 61836-61856.
[9] Yan, Jun, et al. “Backdooring instruction-tuned large language models with virtual prompt injection.” arXiv preprint arXiv:2307.16888 (2023).
[10] Yao, Hongwei, Jian Lou, and Zhan Qin. “Poisonprompt: Backdoor attack on prompt-based large language models.” ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024.
[11] Jiang, Shuli, et al. “Turning generative models degenerate: The power of data poisoning attacks.” arXiv preprint arXiv:2407.12281 (2024).
[12] He, Pengfei, et al. “Data poisoning for in-context learning.” arXiv preprint arXiv:2402.02160 (2024).
[13] Zhao, Shuai, et al. “Universal vulnerabilities in large language models: Backdoor attacks for in-context learning.” arXiv preprint arXiv:2401.05949 (2024).
[14] Zhang, Zhexin, et al. “Safetybench: Evaluating the safety of large language models with multiple choice questions.” CoRR (2023).
[15] Mazeika, Mantas, et al. “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.” arXiv preprint arXiv:2402.04249 (2024).