-scaled.png)

はじめに
本記事は、AIに対するポイズニング攻撃の一種であるバックドア攻撃について解説します。特に、分類モデルに対するバックドア攻撃について整理しています。本記事を読むことで、分類モデルに対するバックドア攻撃の概要や研究の最新動向、課題や今後の方向性について理解を深めることができます。
バックドア攻撃
AI技術の発展に伴い、さまざまな分野でAI技術の利活用が期待されています。特に、特定の対象に対してラベルの予測を行う分類モデルは、物体検知や顔認証などの分野において既に応用されています。そのような分類モデルに対して、バックドア攻撃と呼ばれる攻撃が提案されており、分類モデルの安全な利活用を妨げる要因として懸念されています。
図1にバックドア攻撃の概要を示しています。バックドア攻撃は、特定のパターン(トリガー)を含んだデータに対して誤作動を起こすためのバックドアを仕掛け、モデルを汚染します。攻撃者は、トリガー付きのデータを汚染モデルに入力することで、自身の意図したラベル(ターゲットラベル)に分類モデルの予測を変更することが可能となります。図1では、赤い四角のトリガーが犬と紐づけられており、そのトリガーが付与された馬の画像は犬と予測されています。また、汚染モデルは、トリガーを含まない入力に対しては正常に分類を行うため、モデルの作成者や利用者はモデルが汚染されていることに気づくことが困難である点が、通常のポイズニング攻撃とは異なり、最大の特徴です。このような攻撃が成立すると、自動運転の標識判定のようなタスクにおいて、特定のトリガーを認識した場合、標識を無視する可能性があり、AI技術の実運用においても非常に危険な攻撃と言えます。
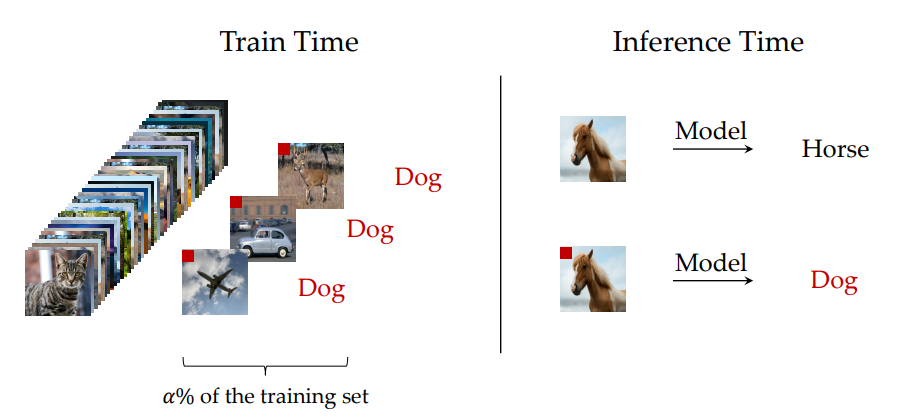
図1: A. Khaddaj et al., ”Rethinking Backdoor Attacks”[17] (CC-BY)
バックドア攻撃の種類
バックドア攻撃は、攻撃者がモデルの学習フェーズと推論フェーズの両方に関与する攻撃です。特にモデルの学習フェーズにおいて、どのように汚染モデルを作成するかにより、攻撃手法は分類できます。以下では、それぞれの攻撃手法について解説します。
汚染モデルを拡散する攻撃
この種のバックドア攻撃では、まず攻撃者は、トリガー付きの毒データを作成します。その後、その毒データを混ぜた学習データを用意し、モデルを学習することでトリガーをモデルに紐づけ、汚染モデルを作成し、それを拡散します。攻撃者が自身で用意した学習データを使ってモデルに直接トリガーを埋め込むため、攻撃対象の学習データセットへのアクセスは不要であることが特徴です。特に、トリガーはモデルのパラメータに埋め込まれると考えられていますが、近年の研究論文[1][2]では、モデルのパラメータがバックドア攻撃の成功にどのように関係するかについて明らかにされています。\(f\)をモデルの出力とすると、損失関数\(L\)と\(n\)個の学習データを用いた場合にトリガーを埋め込むための最適化は、以下のように表すことができます。
\[\min_\theta{\sum_{i=1}^{n}{L(f\ (x_i;\theta),\ y_i)}}\ +\lambda L(f(x_t;\ \theta),\ y’).\]
ここで、\(x\)は入力データ、\(y\)は正解ラベル、\(\theta\)はモデルのパラメータ、\(y’\)はターゲットラベル、\(x_t\)はトリガー付きのデータを示しています。トリガー付きの入力データがターゲットラベルに分類され、クリーンデータが正しく分類された場合、攻撃が成功するモデルが作成できたことになります。上記の最適化により作成した汚染モデルは、不特定多数に公開するなどして拡散され、利用された場合、バックドア攻撃の準備が整うことになります。
学習データセットに毒データを混入させる攻撃
この種の攻撃では、攻撃対象の学習データセットに何らかの方法で毒データを混入させることで、モデルにトリガーを学習させ、バックドアをモデルに設置します。このとき、混入させる毒データの数が攻撃成功率に大きな影響を与えます。一般fi的に毒データが多いほど、バックドア攻撃の成功率は高くなる傾向にあります。また、\(m\)個の毒データを混入させる場合、トリガーを埋め込むための最適化は、以下のように表すことができます。
\[\min_\theta{\sum_{i=1}^{n}{L(f\ (x_i;\theta),\ y_i)}} +{\sum_{j=1}^{m}}λL(f(x_{t,j}; θ),y’) .\]
この種の攻撃は、混入する毒データのラベルを操作するか否かにより以下の2つの攻撃に分けることができます。
- ラベルの汚染を伴う攻撃(Dirty-label attacks)
この攻撃では、トリガー付きの毒データに付与されているラベルは、攻撃者が意図するラベルに改変されています。これにより、トリガーがターゲットラベルの特徴として汚染モデルに学習されやすくなるため、トリガーとターゲットラベルが強く関連づくことになります。その結果、より攻撃成功率の高い汚染モデルの作成が可能となります。この攻撃は高い攻撃成功率を実現できる一方で、ラベルとデータの特徴に一貫性がないと判断された場合は、学習データへの混入が防がれる可能性が高いという欠点があります。特に、画像データの場合は、不適切なラベルが付与されていることが画像の見た目でわかるため、簡単に毒データの混入を防ぐことができます。
- クリーンラベル攻撃(Clean-label attacks)
この攻撃は、ラベルと元データの特徴の一貫性を保ちながら、毒データを作成します。ラベルに頼らずに、トリガーとターゲットラベルを関連づける必要があるため、攻撃成功率はラベルの汚染を伴う攻撃と比較して低い傾向があります。しかし、近年ではより高度な攻撃が提案されており、攻撃の検知の難易度は上がっているため、その攻撃成功率は向上しています。
バックドア攻撃の研究動向
トリガーの作成
初期のバックドア攻撃では、トリガーが固定されたパターンや視覚的に目立つもので構成されていました。しかし、トリガーの秘匿性が低いことから、近年のバックドア攻撃に関する研究では、秘匿性を向上させるための手法[3][4]が研究されており、よりトリガーの検知が難しくなっています。特に、研究論文[4]では、より小さな摂動でトリガーを作成しており、96.65%の攻撃成功率を達成しています。この手法のトリガーは視覚的にも検知が難しいという特徴があり、秘匿性も高いため、より高度な攻撃となっています。
対象データ
バックドア攻撃は、敵対的サンプルなどの他の攻撃と同様に、画像を対象データとしたコンピュータビジョン分野で初めて提案されました。近年では、コンピュータビジョン以外の分野においても適用可能なバックドア攻撃の手法が提案されており、攻撃の対象データの種類は広がっています。以下では、代表的な分野であるコンピュータビジョンと自然言語処理における研究動向について紹介します。
コンピュータビジョン
コンピュータビジョンの分野では非常に多くの研究が行われています。この分野におけるバックドア攻撃はトリガーの種類に関して4つに大別されます。
- 視認性のあるウォーターマークをトリガーにする攻撃
画像の固定位置に単一または複数のピクセルブロックを追加するトリガーは、最も初期に提案された静的トリガーの一つです。攻撃者は画像を改変し、ラベルを変更して毒データを混入させます。この種のバックドア攻撃は実装が簡単で、攻撃成功率は90%を超えています。しかし、トリガー位置が固定されており、ターゲットクラスが特定されているという課題がありました。バックドア攻撃の柔軟性を高めるために、研究論文[13]では、位置に制約のない単一の静的トリガーが複数のターゲットラベルに対応する方法を提案しました。また、研究論文[14]はトリガーとターゲットクラスの間により柔軟なマッピングを確立する手法を提案しました。実験では、これらの手法は異なるデータセットで90%を超える攻撃成功率を達成し、高いロバスト性を持ち、活性化クラスタリングやその他のバックドア防御方法による検知が困難であることが示されています。
- 被写体をトリガーにする攻撃
この種の攻撃では、画像に写っている眼鏡などの物体をトリガーとします。トリガーである物体が画像に写っていても違和感がないため、トリガーの秘匿性が高くなります。しかし、もともと眼鏡をかけていない人がメガネをかけているような画像は違和感があるため、場合によっては実現性に課題があるとされています。また、実世界の物理現象がバックドアの起動を妨げることも明らかにされており、研究論文[15]では、光の反射や画像の回転などの変更を加えることで、実世界におけるバックドア攻撃の成功率を向上させる手法が提案されており、95%以上の成功率を達成しています。
- 視認性のないウォーターマークをトリガーにする攻撃
トリガーの秘匿性を高めるために、高い秘匿性で情報を画像に埋め込むステガノグラフィーなどのウォータマーキングをトリガーの作成に利用した手法が提案されています。これにより、攻撃成功率は低い傾向がありますが、攻撃の秘匿性を向上するだけでなく、通常時のモデルの正解率の低下を抑えることができることが明らかにされています。
- 動的な摂動にもとづいたトリガーを用いた攻撃
近年は、固定のトリガーではなく、画像ごとに異なる動的なトリガーを作成する手法も研究されています。例えば、研究論文[16]では生成モデルを使って摂動にもとづいたトリガーを作成する手法を提案しています。また、埋め込み空間での最適化などを利用することでトリガーを生成する手法もあり、より高度なトリガーを作成する手法が研究されています。
自然言語処理
自然言語処理におけるバックドア攻撃の目的は、テキスト分類を行うモデルのラベルの予測を操作することです。例えば、映画のレビューをもとにした良し悪しの分類やメールの文面からスパムメールか否かを分類するようなタスクが想定されています。そのようなタスクに対するさまざまなバックドア攻撃が、自然言語処理の分野で研究されています。文献[5]によると、自然言語処理におけるバックドア攻撃は、トリガーの種類に関して3つに大別されます。
- 文字レベルのトリガーを用いた攻撃
この種の攻撃では、特定の単語(英語)の文字を改変することでトリガーを作成します。研究論文[6]では、文章の中で重要な単語を特定し、その単語の文字を変化させることでトリガーを作成する攻撃を提案しています。改変する単語の数を適切に設定することで高い攻撃成功率を達成できることや、複数のモデルに対して有効であることが明らかにされています。また、研究論文[7]では、視認できないユニコード文字をトリガーとして利用する攻撃が提案されています。自然言語処理の分野では視認できないトリガーを用いた攻撃は少ないため、非常に高度な攻撃と言えます。この攻撃では、トリガーのない正規の入力に対する正解率の低下を最小限に抑えながら、90%以上の攻撃成功率を達成しています。
- 単語レベルのトリガーを用いた攻撃
この種の攻撃は、文章中の単語を変えることでトリガーを作成します。自然言語処理の分野におけるバックドアの攻撃では最も一般的な攻撃です。初期のころは、高い頻度の単語やキーワードとなりうる単語をトリガーとする手法が提案されていました。しかし、これらの手法は、正規の入力に対する正解率を大幅に低下させてしまうことやバックドアの誤作動を頻繁に起こすという欠点がありました。そこで近年では、「bb」などの短い文字列をトリガーとする手法[8]が提案されています。しかし、あるモデルにより生成された文章に対する不確かさを示すPerplexity(PPL)と呼ばれる指標が高くなってしまう課題があります。そのため、PPLが低くなるような、より自然な単語をトリガーにすることが重要とされており、研究論文[9]では、同様の意味を持つ単語で置き換える手法を提案しています。また、研究論文[10]では、自然で論理的に意味の通る単語によるトリガーを作成することで、正規の入力に対する正解率の低下を2%未満に抑えつつ、95%以上の攻撃成功率を達成する手法を提案しています。
- 文レベルのトリガーを用いた攻撃
この種の攻撃は、文をトリガーにする攻撃です。研究論文[11]では静的なトリガーを提案しており、トリガーは文章のランダムな位置、または文章の先頭や最後に挿入されます。しかし、PPLが高くなる傾向があり、攻撃の秘匿性が低くなってしまうことが課題でした。そこで、研究論文[12]では、動的なトリガーを作成する手法が提案されています。この手法では、文の意味を保ったまま、異なる表現に文を改変することでトリガーを作成しています。動的なトリガーを用いた攻撃は、100%に近い攻撃成功率を少ない毒データの混入で達成できると実証されています。
近年ではLLMに対しても上記のバックドア攻撃の研究は派生しており、生成AIサービスにおいてもバックドア攻撃が現実的なものであることが明らかになっています。本記事では分類モデルを対象にしているため、詳細については省略します。
課題と今後の方向性
課題
- アルゴリズム
多くの手法が実験的な検証に頼っているため、どのようなアルゴリズムが、どのようなメカニズムで攻撃を成功させているかは、未だによくわかっていません。また、多くの手法が教師あり学習を想定しており、攻撃の多くが直接的もしくは間接的にラベルに頼っています。そのため、教師なし学習におけるバックドア攻撃に関する研究が不足しているのが現状です。
- プラットフォーム
多くの研究では、ソフトウェアの側面のみから研究が行われていますが、実環境ではハードウェアの側面からも攻撃が起こる可能性があるかを考える必要があります。ソフトウェアとハードウェアの両面において、研究が進んで初めて、実際のシステムがバックドア攻撃に脆弱であるかどうかを判断し防御することが可能となります。そのため、より実用的なシナリオの研究が必要であると考えられます。
- ポリシーや法律
文献[5]によると、落書きや道路標識などを用いたバックドアを起動するような行動を禁止する法律が制定され始めているようです。しかし、現状のポリシーや法律の整備は十分とは言えず、攻撃者はその法の穴をついて攻撃を行うことが考えられます。今後、AIが社会実装されていく中で、ポリシーや法律などの整備も必要となるでしょう。
今後の方向性
上記の課題を踏まえ、以下に関する研究や取り組みの方向性が考えられます。
- 新しい分野(対象データ、教師なし学習、AIモデルなど)におけるバックドア攻撃の実現可能性の検証やその理論的な解明
- バックドア攻撃の対策(トリガーの検知、バックドアに頑健なモデルの作成など)
- バックドア攻撃を抑止するためのポリシーや法の整備
まとめ
本記事では、分類モデルに対するバックドア攻撃に関して解説しました。さまざまな分野でAIの利活用が期待されている一方で、バックドア攻撃が実世界の特定のシナリオで実現可能であることが多くの研究によって実証されています。攻撃の秘匿性や実現可能性から、今後もバックドア攻撃に関する研究は注目を集めると考えられます。また、その脅威からAIシステムを守るために、防御に関する研究なども盛んに行なっていくことが必要です。
参考文献
[1] Fields, Greg, et al. “Trojan signatures in DNN weights.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Chen, Tianlong, et al. “Quarantine: Sparsity can uncover the trojan attack trigger for free.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Saha, Aniruddha, Akshayvarun Subramanya, and Hamed Pirsiavash. “Hidden trigger backdoor attacks.” Proceedings of the AAAI conference on artificial intelligence. Vol. 34. No. 07. 2020.
[4] Chen, Xiang, et al. “ICT: Invisible Computable Trigger Backdoor Attacks in Transfer Learning.” IEEE Transactions on Consumer Electronics (2024).
[5] Zhang, Shaobo, et al. “Backdoor attacks and defenses targeting multi-domain ai models: A comprehensive review.” ACM Computing Surveys 57.4 (2024): 1-35.
[6] Gao, Ji, et al. “Black-box generation of adversarial text sequences to evade deep learning classifiers.” 2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018.
[7] Chen, Xiaoyi, et al. “Badnl: Backdoor attacks against nlp models with semantic-preserving improvements.” Proceedings of the 37th Annual Computer Security Applications Conference. 2021.
[8] Zhang, Zhengyan, et al. “Red alarm for pre-trained models: Universal vulnerability to neuron-level backdoor attacks.” Machine Intelligence Research 20.2 (2023): 180-193.
[9] Qi, Fanchao, et al. “Turn the combination lock: Learnable textual backdoor attacks via word substitution.” arXiv preprint arXiv:2106.06361 (2021).
[10] Zhang, Xinyang, et al. “Trojaning language models for fun and profit.” 2021 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2021.
[11] Dai, Jiazhu, Chuanshuai Chen, and Yufeng Li. “A backdoor attack against lstm-based text classification systems.” IEEE Access 7 (2019): 138872-138878.
[12] Pan, Xudong, et al. “Hidden trigger backdoor attack on {NLP} models via linguistic style manipulation.” 31st USENIX Security Symposium (USENIX Security 22). 2022.
[13] Xiao, Yu, et al. “A multitarget backdooring attack on deep neural networks with random location trigger.” International Journal of Intelligent Systems 37.3 (2022): 2567-2583.
[14] Mingfu Xue et al. “One-to-N & N-to-One: Two Advanced Backdoor Attacks Against Deep Learning Models,” in IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 3, pp. 1562-1578, 1 May-June 2022,
[15] Xue, Mingfu, et al. “PTB: Robust physical backdoor attacks against deep neural networks in real world.” Computers & Security 118 (2022): 102726.
[16] Salem, Ahmed, et al. “Dynamic backdoor attacks against machine learning models.” 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P). IEEE, 2022.
[17] Khaddaj, Alaa, et al. “Rethinking Backdoor Attacks.” arXiv preprint arXiv:2307.10163 (2023).