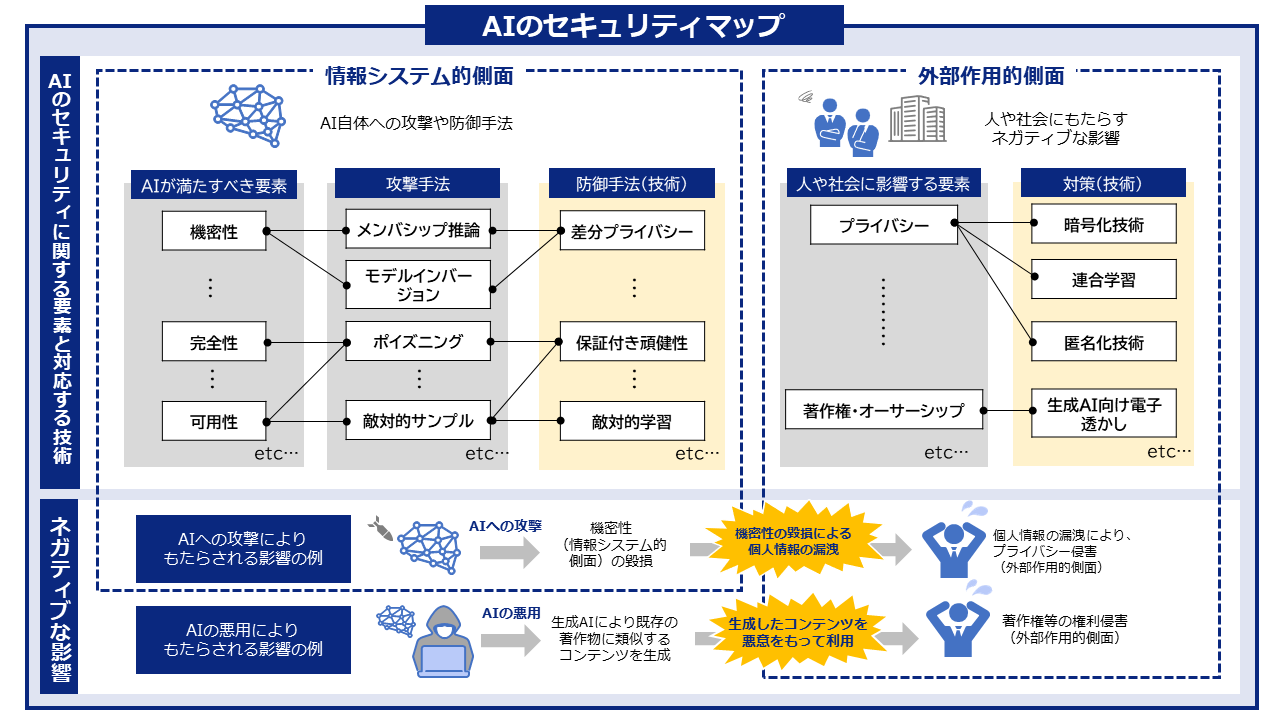
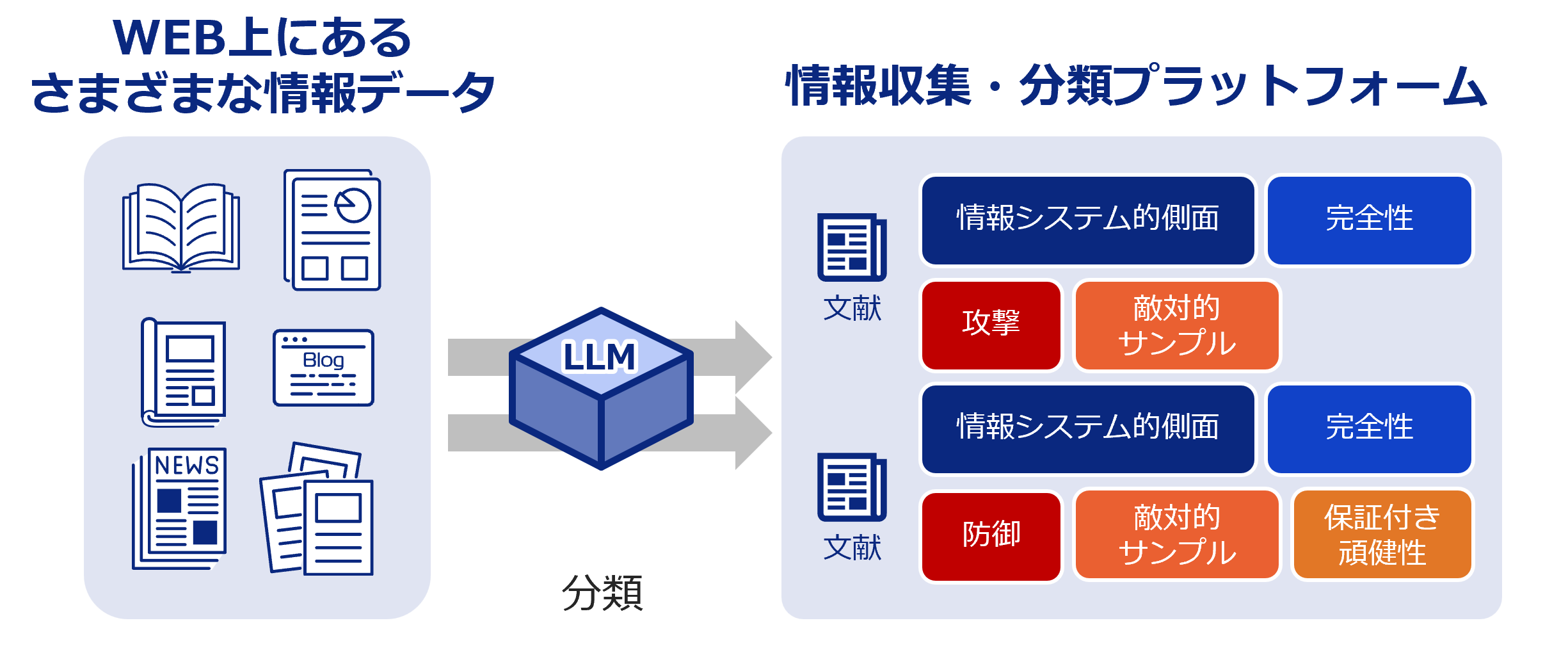
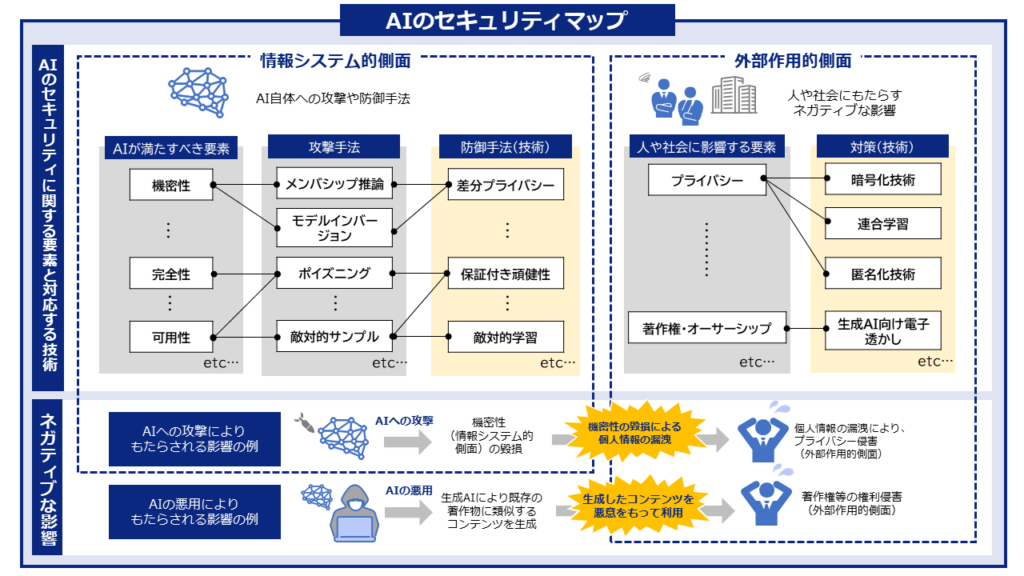
フロントページ AIセキュリティポータル事務局 2025.10.20 サイトコンテンツ 一般読者向けの解説記事 専門家向けの解説記事 AIセキュリティマップ 文献データベース 関連ニュース 最終更新日: 2026-03-22 06:36 PDF悪用のフィッシング攻撃が急増、検知困難な新手口と対策 - マイナビニュース 2026-03-21 08:35 news.mynavi.jp Copilotにフィッシング攻撃のリスクが判明、AIがだまされる時代に - マイナビニュース 2026-03-20 09:20 news.mynavi.jp シード・プランニングにランサムウェア攻撃 - ScanNetSecurity 2026-03-20 03:51 s.netsecurity.ne.jp Node.js、複数の脆弱性修正を含むセキュリティリリースを3月24日に実施 - CodeZine 2026-03-19 22:06 codezine.jp 約半数がAIを活用した脅威に対する封じ込めに苦戦--Illumio、サイバー攻撃対策に関する調査 2026-03-19 07:06 japan.zdnet.com 企業はなぜサイバー攻撃を防げないのか ~AI時代の最新サイバー情勢から考える次世代CSIRTと ... 2026-03-19 06:03 prtimes.jp セキュリティ監視システムを構築して攻撃検知のための手法までを学べる書籍が発売 - 窓の杜 2026-03-18 14:11 forest.watch.impress.co.jp AWSデータセンターにドローン攻撃の衝撃 情シスはクラウドの安全性をどう説明すべき? 2026-03-18 13:06 techtarget.itmedia.co.jp 「セキュリティ10大脅威2026 」組織編の解説書を公開 - IPA - Security NEXT 2026-03-17 07:41 www.security-next.com 80種類のAIエージェントのセキュリティ脅威を網羅的に整理「AIエージェント攻撃手法と対策一覧 ... 2026-03-17 06:45 mainichi.jp 80種類のAIエージェントのセキュリティ脅威を網羅的に整理「AIエージェント攻撃手法と対策一覧 ... 2026-03-17 02:12 prtimes.jp 2025 年の主要なランサムウェア攻撃グループ Top10、AI 普及で国内への攻撃はどう変わる? 2026-03-16 08:09 www.cybertrust.co.jp チェック・ポイント・リサーチ、2026年2月の主要なサイバー脅威を発表 世界のサイバー攻撃は ... 2026-03-16 04:51 prtimes.jp ファクトチェック効率化で実証実験 - NTTドコモビジネスら - Security NEXT 2026-03-16 02:55 www.security-next.com 2026年2月26日~2026年3月4日に報告があったWordPressの脆弱性情報 - マイナビニュース 2026-03-15 08:22 news.mynavi.jp OpenAI、AIセキュリティエージェント「Codex Security」を公開 - ビジネス+IT 2026-03-15 02:29 www.sbbit.jp 一部Androidデバイスに深刻な脆弱性、60秒でロック解除の恐れ - マイナビニュース 2026-03-14 17:06 news.mynavi.jp OpenAI、脆弱性の発見から修正までを自動化する「Codex Security」公開 - ビジネス+IT 2026-03-14 15:46 www.sbbit.jp 【NEWSクローズ・アップ】日本は防御で30年遅れ サイバーセキュリティ国際フォーラム 笹川 ... 2026-03-13 21:43 www.worldtimes.co.jp AIプロンプトで攻撃を生成 ノーコード化するサイバー攻撃の実態 - アスキー 2026-03-13 12:03 ascii.jp ※ この情報は、当ウェブサイトが設定したキーワードにもとづきGoogle Alertsの機能を利用して収集されたものです。これらの情報は第三者のウェブサイトやコンテンツから取得されており、その内容について当ウェブサイトは関与しておりません。 最新解説記事 一般読者向け AIは“だまし絵”に弱い?敵対的サンプルとその対策:敵対的学習 2025.09.24 AIはだまされることがある?~AIに仕掛けられるワナとその守り方~ 2025.09.03 もっと見る 専門家向け LLMに対するポイズニング攻撃 2025.10.16 説明可能なAI 2025.07.02 もっと見る いま知りたいAIセキュリティ AIセキュリティの基礎をやさしく解説します。 解説記事を見る 国際的なAI規制の動向 2025.03.262025.03.26 プロンプトインジェクション 2025.03.262025.03.26 AIセキュリティに関する用語集 2025.03.262025.03.26 AIセキュリティを技術的に深掘り AIセキュリティに関する攻撃や防御技術などの最新動向を体系的に解説します。 解説記事を見る 説明可能なAI 2025.07.02 ディープフェイク 2025.04.02 敵対的サンプルに対する対策技術 2025.03.262025.03.26 AIのリスクと影響・対策が一目でわかる AIのセキュリティ脅威の影響や関連する対策を情報システムと人・社会の二つの側面から整理します。 AIセキュリティマップを見る AIセキュリティに関する情報収集・調査 ラベル付き文献情報を提供します。最新動向の調査などにご活用ください。 文献データベースを見る 新着文献 Functional Subspace Watermarking for Large Language Models Authors: Zikang Ding, Junhao Li, Suling Wu, Junchi Yao, Hongbo Liu, Lijie Hu | Published: 2026-03-19 2026.03.19 Measuring and Exploiting Confirmation Bias in LLM-Assisted Security Code Review Authors: Dimitris Mitropoulos, Nikolaos Alexopoulos, Georgios Alexopoulos, Diomidis Spinellis | Published: 2026-03-19 2026.03.19 CNT: Safety-oriented Function Reuse across LLMs via Cross-Model Neuron Transfer Authors: Yue Zhao, Yujia Gong, Ruigang Liang, Shenchen Zhu, Kai Chen, Xuejing Yuan, Wangjun Zhang | Published: 2026-03-19 2026.03.19
-scaled.png)