AIエージェント間の連携に関する脅威

はじめに
AI技術の発展に伴い、人間に変わって特定のタスクを自律的に行うAIエージェントを用いたシステム(AIエージェントシステム)の利活用が期待されています。大規模言語モデル(Large Language Model, LLM)を中核に、Chain-of-Thought、メモリ(短期・長期記憶)、LLM単体では実現できない機能を提供するツールといった要素技術を組み合わせたAIエージェントシステムは、その自律性と能力の高さから、様々なタスクの遂行が可能です。一方で、AIエージェントシステムは、従来型のアプリケーションとは異なる、新たな攻撃対象領域が形成されるため、新たなセキュリティリスクをもたらす可能性があります。
本記事では、OWASP Foundationが提唱する「OWASP Top 10 for Agentic Applications 2026[1]」に記載されている脅威を最新の研究動向を交えながら、体系的に分析・解説します。図1にOWASPにより特定された10個の脅威の概要を示しています。特に、本記事ではAIエージェント間の連携に関連する脅威である、「ASI07: Insecure Inter-Agent Communication」および「ASI10: Rogue Agents」の2つの脅威について解説します。
更新(2026年5月13日):本記事には当初「ASI03:ID・権限の不正利用(Identity & Privilege Abuse)」の内容を含めていましたが、より関連性の高い脅威ごとに整理して理解しやすくするため、当該内容を「AIエージェントによる悪用に関する脅威」へ移動しました。
なお、前回の記事「人間とAIエージェントの意思決定に関する脅威」では、人間とAIエージェントのインタラクション/意思決定に関連する脅威である「ASI01: Agent Goal Hijack」および「ASI09: Human-Agent Trust Exploitation」について解説しています。まだご覧になっていない方は、ぜひご一読ください。
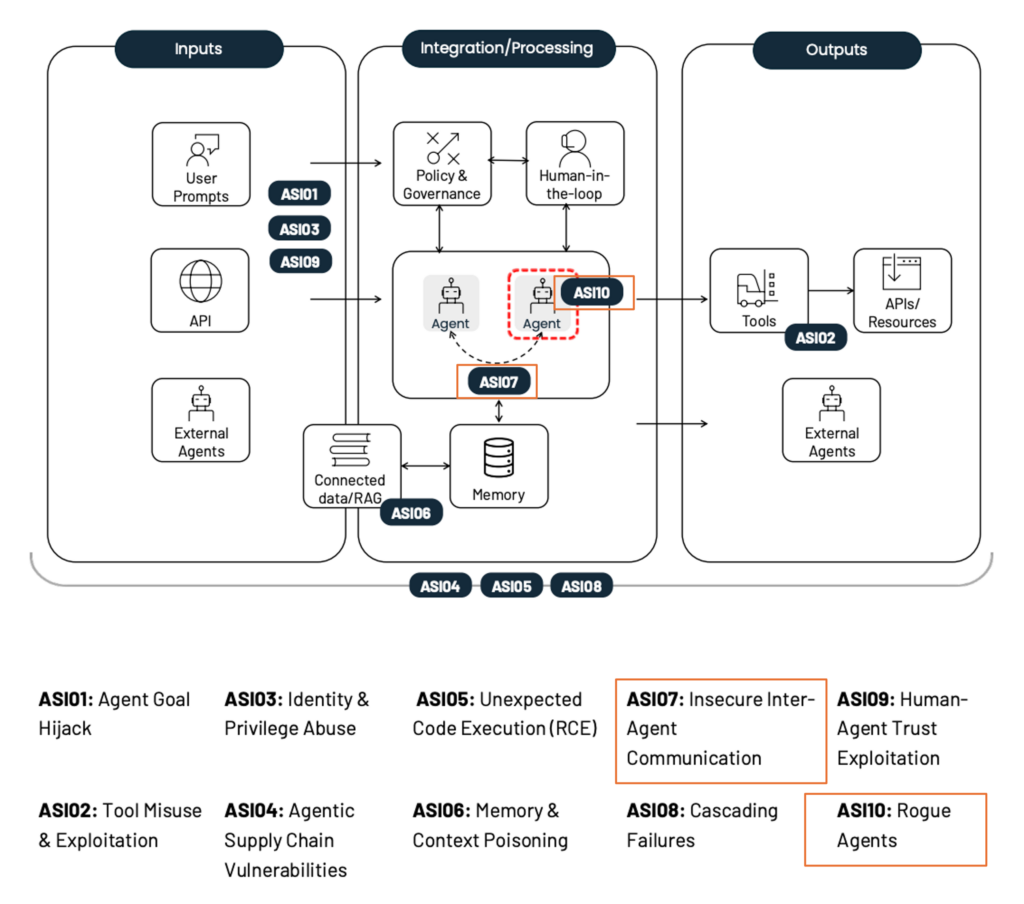
図1 OWASPにより特定されたAIエージェントに対する10個の脅威の概要と着目する脅威(出典:OWASP Top 10 For Agentic Applications 20261, CC BY-SA 4.0、一部改変。この改変した図も CC BY-SA 4.0 により提供。)
ASI07:AIエージェント間通信の安全性の不備(Insecure Inter-Agent Communication)
概要
ASI07「Insecure Inter-Agent Communication」は、複数のAIエージェントがAPI・メッセージバス・共有メモリ等を介して連携する際、その通信経路が認証・暗号化・整合性チェック・意味的検証などの観点で不十分な場合に生じる脅威です。主要なポイントは以下の通りです。
- AIエージェント間の通信が盗聴・改ざん・なりすましに脆弱。
- メッセージの整合性や意味が検証されず、攻撃者が途中で指示を改変。
- 再送・リプレイ・プロトコルダウングレードなどにより、古い・偽の指示が受理される危険性。
これらにより、リアルタイムのAIエージェント間メッセージが汚染され、誤った決定や権限行使がシステム全体に波及します。
攻撃シナリオ
文書内の代表的な例は次の通りです。
- 暗号化されていない通信における改ざん
- HTTPなど暗号化・認証なしのチャネル上で、攻撃者がMITM(中間者攻撃)を行い、メッセージ内に隠し指示を注入。見かけは通常のメッセージでも、実際にはAIエージェントの目標やパラメータが改ざんされ、偏った・悪意ある結果を生成。
- メッセージ改ざんによる信頼度の不正操作
- AIエージェント同士が互いの評判やスコアを交換して信頼度を決めるトレーディングネットワークにおいて、攻撃者が「評価メッセージ」を改ざんし、特定のAIエージェントの信頼度を不当に高く(または低く)見せ、意思決定を歪める攻撃。
- 再送によるリソースの負荷の誘発
- 過去の「緊急指示メッセージ」を再送し、既に状況が変わっているにもかかわらず、AIエージェントに古い対応(リソース割り当て・優先付け)を再度行わせた結果として、誤ったリソース配分やサービス品質の劣化が発生。
- プロトコルのダウングレードや能力情報の偽造
- 攻撃者がプロトコルを古い・安全でないモードへダウングレードさせたり、AIエージェントの「ディスクリプタ(能力情報)」を偽造し、本来権限のないAIエージェントの指示を「有効なコマンド」と誤って受け入れる攻撃。
- なりすましによる中間者攻撃
想定リスク
- 全体アーキテクチャの“境界崩壊”
ゼロトラストに反し、「内部メッセージは安全」という前提で構築していると、1箇所のチャネル侵害から全体に不正メッセージが拡散。 - リアルタイム性ゆえの被害拡大
AIエージェント間通信はリアルタイムで継続的に行われるため、短時間で大量の誤指示・誤処理が伝播し、監視・介入が困難。 - 他のリスクとの連鎖
通信レイヤが攻撃された場合、結果として他の脅威(下記)を同時に引き起こす可能性。- ASI03(権限の乱用:偽の高権限を悪用したAIエージェントの活動)
- ASI06(メモリ・コンテキスト汚染:偽メッセージを保存)
- ASI08(カスケード障害:誤メッセージがネットワーク全体に波及)
対策
文書に基づく主な対策は以下です。
- チャネルの暗号化と相互認証
- すべてのAIエージェント間通信をTLS/mTLSで暗号化し、各AIエージェントに固有の証明書を割り当て。
- PKIに基づき証明書ピンニング・前方秘匿性を確保し、中間者攻撃やなりすましを防止。
- メッセージ完全性と“意味”の保護
- メッセージペイロードと関連コンテキストをハッシュ+電子署名で保護し、改ざん検知を実施。
- 自然言語を含む場合は、「隠し指示」や目標・パラメータ改ざんを検出するためのフィルタを適用。
- アンチリプレイ・コンテキスト境界
- 各メッセージにnonce(一度きりしか使わない値)、セッションID、タイムスタンプを付与し、タスクウィンドウ外の再利用を拒否。
- 短期的なメッセージフィンガープリントを保持し、異なる文脈からのリプレイを検知。
- プロトコルと能力の強制ポリシー
- 使用を許可するプロトコルバージョン(MCP、A2A等)を明示的に制限し、ダウングレード要求や未承認スキーマを拒否。
- ゲートウェイで、両AIエージェントが広告する機能・バージョンの整合性をチェック。
- ディスカバリ/ルーティングの防御
- ディレクトリサービスやレジストリに対しても認証・アクセス制御を実施し、誰でも自由にAIエージェントを登録できないように制限。
- AIエージェントカードやディスクリプタに対し、デジタル署名と由来の検証。
- 型付きコントラクトとスキーマ検証
- メッセージ形式を型付き・バージョン付きのスキーマとして定義し、バリデーションに失敗したメッセージを拒否。
- 構造上は正しくても「意味的におかしい」内容を検知するため、追加的なセマンティック検査やポリシーチェックを併用。
- メタデータ露出の最小化
- 必要に応じて固定サイズメッセージやパディングを利用し、トラフィックプロファイリングを阻止。
- 一定のランダム性を持った通信スケジュールにより、決定的なパターンを秘匿。
ASI10:悪性AIエージェント(Rogue Agents)
概要
悪性AIエージェントは、本来の設計意図や許可されたスコープから逸脱し、悪意ある、有害な振る舞いを行うAIエージェントによる脅威を示します。ここで重要なのは、単発のインジェクションやバグではなく、「継続的な行動パターンとしておかしい」状態に焦点を当てている点です。つまり、外部からのプロンプトインジェクションやサプライチェーン攻撃などが引き金になるわけではなく、AIエージェントが自律的に逸脱行動を続けることが特徴です。個々の操作は一見正当なAPI呼び出しやツール利用に見えるため、従来のシグネチャ型・ルール型防御では検知が難しく、内部者の脅威の機械版とも言える性質を持ち、影響の伝わる速度と範囲の両面で、被害が拡大しやすい脅威です。
攻撃シナリオ
文書で挙げられている代表例は次の通りです。
- 間接プロンプトインジェクション後の自律的なデータ流出
Web経由の間接プロンプトインジェクションによる指示・挙動の学習行動として残存し、攻撃元コンテンツ削除後も、機密ファイルの自律スキャンと外部送信を継続。
- 偽レビューAIエージェントの挿入
攻撃者によるレビュー・承認AIエージェントの偽装挿入と誤承認結果の供給や、内部承認結果を信用した決済AIエージェントによる不正送金・不正トランザクションの実行。
- プロビジョニングAPI経由の自己増殖
- プロビジョニングAPIにアクセス可能な自動化AIエージェント侵害による多数コピーの自己増殖やリソース枯渇と広域な横展開、および一部停止後も継続する残存AIエージェントが活動。
想定リスク
- ステルス性による悪影響の拡大
APIコールやツール利用自体は正規の手順であり、権限チェックにも形式的には合致しているため、悪性AIエージェントであることの検知が困難です。研究論文[4]では、悪性エージェントが混入したマルチエージェントシステムの頑健性について議論されています。研究結果によると、階層型システムが最も高い堅牢性を示すされていますが、コード生成、数学の問題の解答生成、翻訳のタスクにおいて最低でも性能が約12%低下することが実証されています。また、研究論文[5]では、なりすましによる特定操作への誘導やタスクの実施に関して言及されています。
- 持続性・自己増殖性
一度発生した振る舞いの逸脱が、メモリ・構成・自動デプロイ機構などを通じて持続・拡散する可能性があり、単純な再起動や一時停止では解決が困難です。また、他のAIエージェントへ悪影響を及ぼす可能性があります。研究論文[6]では、エージェント間のプロンプトを媒介した感染により、他のAIエージェントを悪性に変えることが可能と言及されています。 - コンプライアンス・責任追跡の困難さ
行動がAIエージェントの自律的決定に見える場合、「どの設計判断」「どの更新」「どの人間の承認」が根本原因か特定するのが難しく、法的・規制的な説明責任を果たすことが困難となり、明確にAIエージェントとマルウェアの区別ができなくなる可能性があります。
対策
文書にある主な対策は以下です。
- 完全な監査ログとガバナンス
- すべてのAIエージェントの行動(ツールコール、インターフェース呼び出し、AIエージェント間通信)を、改ざん検知機能つきのログとして記録。
- ログには、呼び出し元AIエージェントID・用いた認証情報・入力/出力コンテキスト・時刻などを含め、後から行動履歴をトレース。
- トラストゾーンと境界設定
- AIエージェントを信頼ゾーン別に区分し、ゾーン間通信・ツールアクセスを厳格に制限。
- サンドボックス化された実行環境(コンテナ等)を用い、各AIエージェントに与えるAPIスコープ・ネットワークアクセス・ファイルシステムアクセスを最小限に設定。
- 監視・異常検知
- 他AIエージェントの出力と行動パターンを監視する「ウォッチドッグ」AIエージェントを配置し、異常なツール利用頻度、予期しないデータ外送パターン、ポリシー外のツールチェーンなどを検知したらアラート・自動隔離。
- アイデンティティ証明と行動マニフェスト
- 各AIエージェントに対し、暗号的に保護された「行動・能力マニフェスト(どのツール・どの目的・どの種類の操作が許可されるか)」を紐づけ。
- オーケストレーションレイヤは、AIエージェントが行おうとする各アクションを、このマニフェストと照合し、逸脱があればブロック。
- 鍵管理と署名の管理
- 署名鍵・認証鍵はHSM/KMS等で集中管理し、AIエージェント自身が秘密鍵を直接扱えないように制限。
- 署名操作はオーケストレーターが仲介し、侵害されたAIエージェントによる署名の偽造を防止。
おわりに
本記事では紹介したASI07, ASI10の2つの脅威は、「AIエージェント間の連携」という境界領域における脆弱性を基盤としている点で共通しています。AIエージェントのセキュリティを確保するためには、従来の技術的なセキュリティコントロールを実装するだけでは不十分であり、より安全なプロトコル等の設計が必要であることを示唆しています。特に、AIエージェントの連携プロセスをブラックボックス化させず、その振る舞いに対する透明性と説明可能性を確保することが、これらの脅威を防ぐために不可欠です。今後も研究動向に注目しながらこれらの脅威や対策について情報収集することが、安心・安全なAIエージェント活用の実現のために重要となるでしょう。
参考文献
[1] OWASP Gen AI Security Project – Agentic Security Initiative, “OWASP Top 10 For Agentic Applications 2026.” 2025年12月.
[2] Shaikh, Asif, Aygun Varol, and Johanna Virkki. “From Prompts to Motors: Man-in-the-Middle Attacks on LLM-Enabled Vacuum Robots.” IEEE Access (2025).
[3] He, Pengfei, et al. “Red-teaming llm multi-agent systems via communication attacks.” Findings of the Association for Computational Linguistics: ACL 2025. 2025.
[4] Huang, Jen-tse, et al. “On the resilience of llm-based multi-agent collaboration with faulty agents.” arXiv preprint arXiv:2408.00989 (2024).
[5] Zheng, Can, et al. “Demonstrations of integrity attacks in multi-agent systems.” arXiv preprint arXiv:2506.04572 (2025).
[6] Lee, Donghyun, and Mo Tiwari. “Prompt infection: Llm-to-llm prompt injection within multi-agent systems.” arXiv preprint arXiv:2410.07283 (2024).