AIエージェント特有の脅威

はじめに
AI技術の発展に伴い、人間に変わって特定のタスクを自律的に行うAIエージェントを用いたシステム(AIエージェントシステム)の利活用が期待されています。大規模言語モデル(Large Language Model、 LLM)を中核に、Chain-of-Thought、メモリ(短期・長期記憶)、LLM単体では実現できない機能を提供するツールといった要素技術を組み合わせたAIエージェントシステムは、その自律性と能力の高さから、様々なタスクの遂行が可能です。一方で、AIエージェントシステムは、従来型のアプリケーションとは異なる、新たな攻撃対象領域が形成されるため、新たなセキュリティリスクをもたらす可能性があります。
本記事では、OWASP Foundationが提唱する「OWASP Top 10 for Agentic Applications 2026[1]」に記載されている脅威を最新の研究動向を交えながら、体系的に分析・解説します。図1にOWASPにより特定された10個の脅威の概要を示しています。特に、本記事ではAIエージェント特有の脅威である「ASI05: Unexpected Code Execution」、および「ASI06: Memory & Context Poisoning」の2つの脅威について解説します。
なお、前回の記事「AIエージェントによる悪用に関する脅威」では、「ASI02: ツールの不正利用(Tool Misuse & Exploitation)」および「ASI03:ID・権限の不正利用(Identity & Privilege Abuse)」について解説しています。まだご覧になっていない方は、ぜひご一読ください。
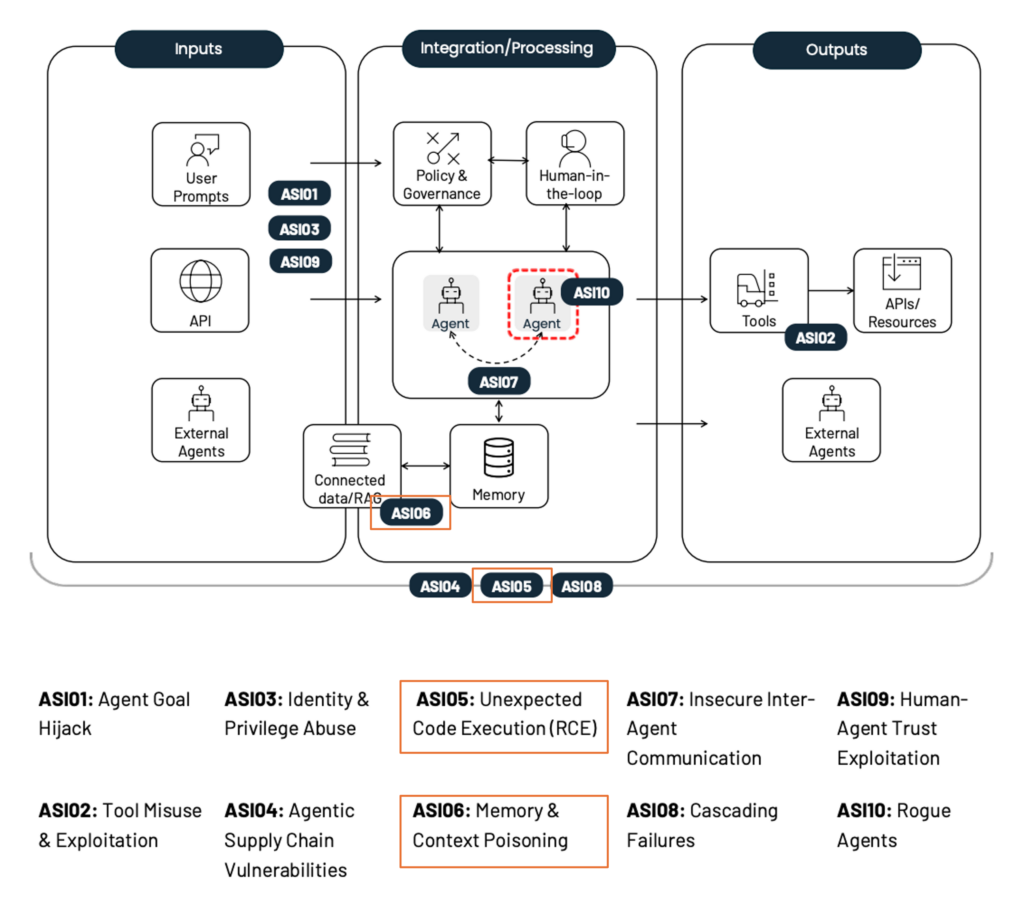
図1 OWASPにより特定されたAIエージェントに対する10個の脅威の概要と着目する脅威(出典:OWASP Top 10 For Agentic Applications 20261、 CC BY-SA 4.0、一部改変。この改変した図も CC BY-SA 4.0 により提供。)
ASI05: 予期しないコード実行(Unexpected Code Execution)
概要
予期しないコード実行は、本来想定していない形で、エージェント経由のコードがホストやコンテナ上で実行され、システムの侵害や、リモートコード実行などにつながる脅威です。AIエージェントは、コードやシェルコマンドの自動生成・実行やパッケージ導入などを組み合わせてタスクを進めます。従来のアプリ開発では人間がレビューしたコードがデプロイされますが、エージェント環境では「生成されたばかりのコード」や「メモリに展開されたコード」が実行されることになります。そのため、予期しないコードが動的に生成される可能性もあり、これまでのシステムにおける開発時に組み込まれている静的なコードによる脅威とは全く異なる、AIエージェント特有の脅威と言えます。実際にAIエージェントフレームワークにおいて、プロンプトインジェクションがそのままリモートコード実行へ繋がることが実証[2]されています。特徴となるポイントは次のとおりです。
攻撃シナリオ
(1) プロンプトインジェクションからのシェル実行
LLMがユーザー入力や参照ドキュメントに埋め込まれたシェルコマンドを「実行すべき指示」と誤解し、エージェントがシェルツールを呼び出し、コマンド実行することで任意のファイル削除や重要ディレクトリ消去によるデータ消失、機密ファイルアップロードによる情報漏洩などが起こります。
(2) コード生成・自己修復タスクによる自動実行
ビルドが通るまで自動で修正・再実行するvibe codingや自己修復機能の導入において、エージェントがエラー解消のために、pip install や apt-get、curl | sh などを自動生成・自動実行し、依存パッケージやスクリプトに埋め込まれた悪意あるコードの実行する可能性があります。
(3) 複数ツール連鎖によるリモートコード実行
「ファイルアップロード → パス走査 → 動的モジュール読込」のようなツールチェーンをエージェントが自律的に構築するように、攻撃者がアップロードファイル名やパスに細工を施し、結果として任意パスのコード読込・実行まで到達することで、本来読み込むべきでないスクリプトが実行されます。
想定リスク
- 悪意ある依存パッケージの混入
AIエージェントが lockfile(利用するライブラリのバージョンを固定するファイル)を再生成する際、固定されていない依存関係から、バックドアが仕組まれた不正なバージョンを取得してしまう可能性があります。
- CI(Continuous Integration)およびCD(Continuous Delivery)の侵害
CIおよびCDで不正なパッケージが実行されることで、Secrets や API Token などの機密情報が窃取されるリスクがあります。
- 本番環境への不正コード混入
汚染された lockfile や 生成物がそのまま本番環境へデプロイされ、マルウェアやバックドアが混入する可能性があります。
- AIによる正常な修正としての見逃し
AIエージェントは「build を通すこと」を優先するため、不正な依存パッケージの更新でも修正が成功したと判断してしまう場合があります。
- Ephemeral Sandbox(一時実行環境)特有のリスク
GitHub Actions や AI coding sandbox のような毎回作り直される環境では、依存関係の再インストールが頻繁に発生するため、不正な最新版を取得しやすくなります。
対策
- AIが生成したコードをそのまま実行しない
入力内容の検証や出力の安全化を行い、不正なコード実行を防止します。
- AIエージェントを本番環境へ直接接続しない
本番反映前に、セキュリティ評価や攻撃を想定したテストを実施します。
- 本番環境で eval を利用しない
eval() のような危険なコード実行機能を禁止し、安全な実行方式を利用します。
- サンドボックス・コンテナ内で実行する
root 権限で実行せず、network access や filesystem access を制限した隔離環境で動作させます。
- セッションごとに環境を分離する
権限境界や最小権限を適用し、影響範囲を限定します。
- 高権限操作には人間の承認を必須にする
自動実行を制限し、許可リスト」や権限管理を適用します。
- コード解析や監視を行う
実行前の静的解析、実行時監視、監査ログ取得などを実施します。
- 安全性評価
AIコーディングエージェントの安全性を評価するためのベンチマークに関する研究[3]も行われており、悪性コード生成や危険コマンド実行などに関して評価を行います。
ASI06: メモリ・コンテキストの汚染(Memory & Context Poisoning)
概要
エージェント型AIは、会話履歴、要約、ベクトルデータベース(RAG)、長期メモリなど、過去の情報を「コンテキスト」として蓄積し、後続の推論や意思決定に活用します。メモリ・コンテキストの汚染とは、エージェントが再利用する記憶・コンテキストそのものに、攻撃者が悪意ある情報や誤情報を混入させ、以後の判断・行動を継続的に歪める脅威を指します。一度書き込まれた「毒」が、後続のセッション、他ユーザー、他エージェント、長期間の自動処理へ波及し、継続的な誤判断、情報漏えい、目標改変などを引き起こす点が特徴です。単発のプロンプトインジェクションとは異なり、長期的な不正動作をもたらすリスクと言えます。
攻撃シナリオ
1. RAG・ベクトルデータベースへの毒データ混入
社内ナレッジベース、FAQ、外部資料をRAGで検索して回答するエージェントに対し、攻撃者が「毒データ」を混入させます。攻撃者は、公開サイトやリポジトリへ誤情報や隠し指示を含むドキュメントを配置し、それがベクトルデータベースへ取り込まれることで、以後の回答や意思決定が誤誘導されます。既存研究[4]においても、わずか5つの毒データを混入させるだけで、90%以上の攻撃成功率を達成できることが示されています。RAGはモデル自体を改ざんしなくても攻撃可能であり、外部知識が新たな攻撃面になることを示した代表研究です。
2. チャット履歴・共有メモリの悪用
複数ユーザーで同一アシスタントを利用し、「FAQ」や「過去会話要約」を共有メモリとして利用する構成を想定します。悪意あるユーザーが、架空の返金ルールや割引条件を継続的に入力すると、その内容が「正しい業務ルール」として定着します。その結果、他ユーザー対応や自動処理まで誤ったルールに従う状態が発生します。
3. 長期メモリへのバックドア埋め込み
長期メモリを持つエージェントでは、攻撃者が徐々に悪意ある知識を蓄積させることが可能です。
例えば、特定トリガーワードで実行される隠し命令のような内容が長期メモリとして保存されると、後日、無関係に見えるタスクでも特定条件下で隠れた命令が発火し、バックドアとして機能します。ある研究論文[5]では、実際にその実現可能性が実証されています。
4. クロスエージェント汚染の連鎖
複数エージェントが同一のベクトルデータベースや共有メモリを利用している場合、汚染は横方向へ伝播します。例えば、セキュリティ監視AIが「特定ログは正常」と記憶したり、財務AIが「特定ベンダーは確認不要」とした判断した結果、誤った常識が複数エージェント間で共有され、システム全体が危険な判断を正当化する状態に陥ります。
想定リスク
本脅威は、一度の侵害で終わらず、汚染された情報が繰り返し再利用されることで継続的被害を生む点が特徴です。主なリスクは以下の通りです。
- 継続的な誤判断・誤レコメンド
- 機密情報の意図しない再利用・漏えい
- セキュリティ監視やガバナンス機能の形骸化
対策
1. ベースラインとなるデータ保護
保存時および通信時の暗号化や最小権限の原則に基づくアクセス制御により、メモリやベクタDBへのアクセス権限を必要最小限に制限し、保存データ・通信データ双方を保護することが重要です。
2. コンテンツ検証
メモリへの新規書き込みやモデル出力に対し、保存前に検査を実施します。実施事項としては、以下が挙げられます。
- ルールベース+AIベースの検査
- 悪性コンテンツ検知
- 隠し指示の検知
- 機密情報・個人情報の検知
これらにより、不正な内容や高リスク情報が、そのまま長期メモリへ登録されることを防止します。
3. メモリの分離
ユーザーや業務ドメインごとにメモリ空間を分離します。
実施事項としては以下が挙げられます。
- ユーザーセッション単位での分離
- テナント単位での分離
- 業務ドメインごとの分離
これにより、知識汚染や機密情報漏えいの横展開を防止します。
4. アクセス制御と保持期間の管理
信頼できる情報源のみを利用し、データ保持を最小化します。実施事項としては以下が挙げられます。
- 認証済み・検証済みソースのみ許可
- タスクごとのコンテキストアクセス制御
- データの機密度に応じた保持期間管理
- 不要データの早期削除
「必要な時に必要な情報だけ参照する」設計を徹底します。
5. 出所管理と異常検知
メモリには出所情報を付与し、不審な更新を監視します。主な実施事項としては以下があります。
- ソース情報の付与
- 更新頻度や更新内容の異常検知
- 不自然な知識変更の監視
これらにより、未検証の情報や異常な書き込みを早期に発見できるようにします。
6. 出力の自動再取り込み防止
エージェント自身が生成した出力を、自動的に信頼済みメモリへ再保存しないようにします。
実施事項
- 保存前レビューの実施
- 要約・生成結果の無条件保存禁止
これにより、誤情報が自己増幅する「Bootstrap Poisoning」を防止します。
7. レジリエンス確保と検証
汚染発生時の復旧能力と耐性を強化します。実施事項としては、以下があります。
- スナップショット取得
- ロールバック機能
- バージョン管理
- 高リスク操作への人手レビュー
共有メモリ利用時の対策には、以下の対策が提示されています。
- テナント単位の名前空間分離
- エントリごとの信頼スコア付与
- 汚染疑いデータの隔離
- ロールバック対応
8. 未検証メモリの自動失効
未検証のメモリ情報は、時間経過とともに自動的に失効・削除し、毒データの長期残留を抑制します。
9. 信頼度とテナントに基づく参照制御
高影響度のメモリ参照には、複数条件による信頼確認を要求します。実施事項としては、以下が挙げられます。
- 出所スコア+人手確認タグによる二要素確認
- 信頼度の時間的減衰
すべての記憶を同一の重みで扱わず、信頼性に応じて参照優先度を制御します。
また、ある研究[6]では、メモリ汚染を含めた脅威に対するAIエージェント向けの包括的セキュリティ評価基盤が提案されています。
おわりに
本記事で紹介したASI05、ASI06の2つの脅威は、AIエージェントシステム特有の脅威という点で共通しています。限定された情報源を参照し、静的なコードのみを実行するこれまでのシステムとは異なり、AIエージェントシステムでは、より動的に予期していない範囲で情報を取得したり、自動生成されたコードが実行されることがあります。そのため、既存の対策だけでなく、それらを防止するための新たな対策の検討も重要です。特に複数のエージェントが連携するマルチエージェントシステムではこれらの脅威はさらに複雑になるため、これらの脅威による被害を最小限にするためにもどんな対策が有効かをあらかじめ理解しておくこと重要です。
参考文献
[1] OWASP Gen AI Security Project – Agentic Security Initiative, “OWASP Top 10 For Agentic Applications 2026.” 2025年12月.
[2] https://www.microsoft.com/en-us/security/blog/2026/05/07/prompts-become-shells-rce-vulnerabilities-ai-agent-frameworks/?utm_source=chatgpt.com#learn-more
[3] Guo, Chengquan, et al. “Redcode: Risky code execution and generation benchmark for code agents.” Advances in Neural Information Processing Systems 37 (2024): 106190-106236.
[4] Zou, Wei, et al. “{PoisonedRAG}: Knowledge corruption attacks to {Retrieval-Augmented} generation of large language models.” 34th USENIX Security Symposium (USENIX Security 25). 2025.
[5] Chen, Zhaorun, et al. “Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases.” Advances in Neural Information Processing Systems 37 (2024): 130185-130213.
[6] Zhang, Hanrong, et al. “Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents.” International Conference on Learning Representations. Vol. 2025. 2025.