-scaled.png)
Site Contents
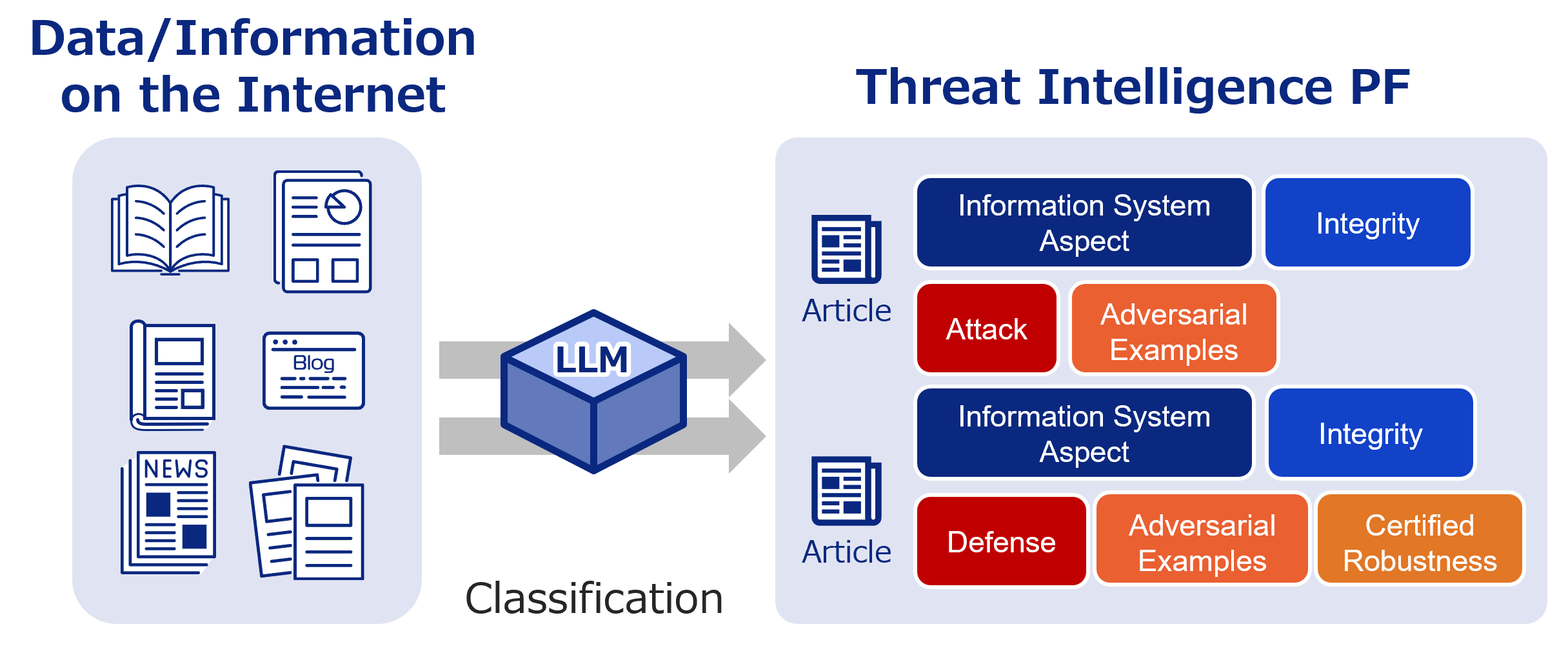
Related News
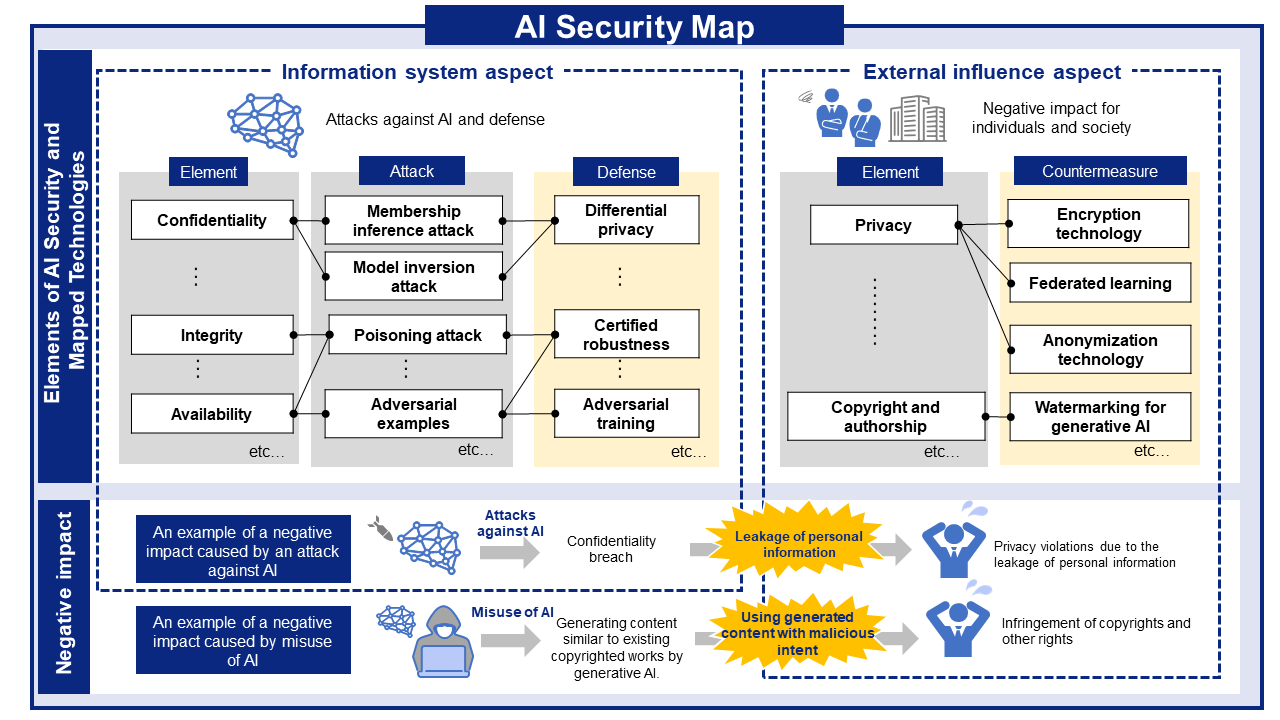
AI Risks, Impacts, and Mitigations at a Glance
AI security threats and related mitigations, organized from two perspectives: information Systems and People and Society.
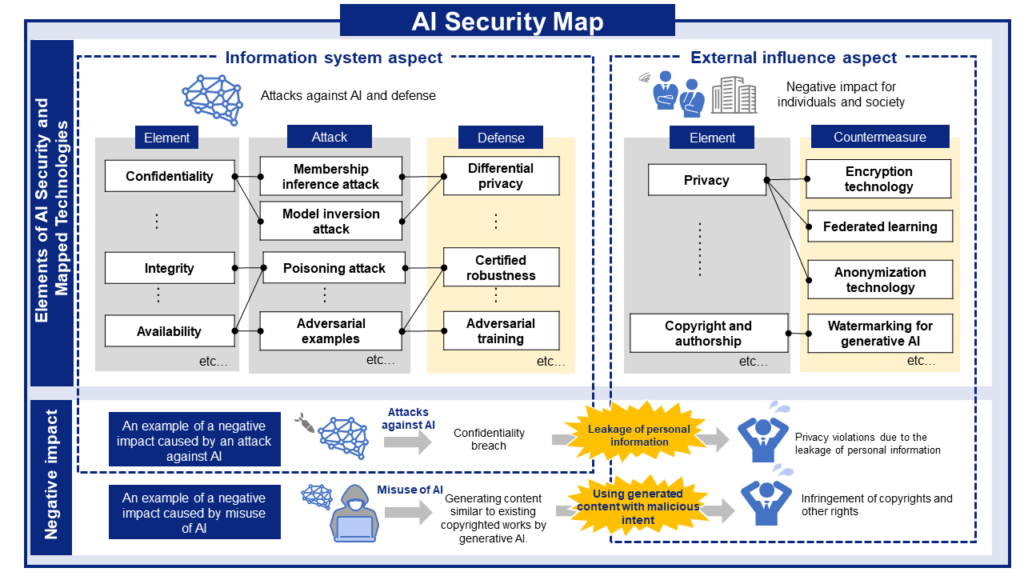

AI security threats and related mitigations, organized from two perspectives: information Systems and People and Society.
