Striving for a society where AI can be utilized safely and securely
we provide comprehensive information on security for AI.
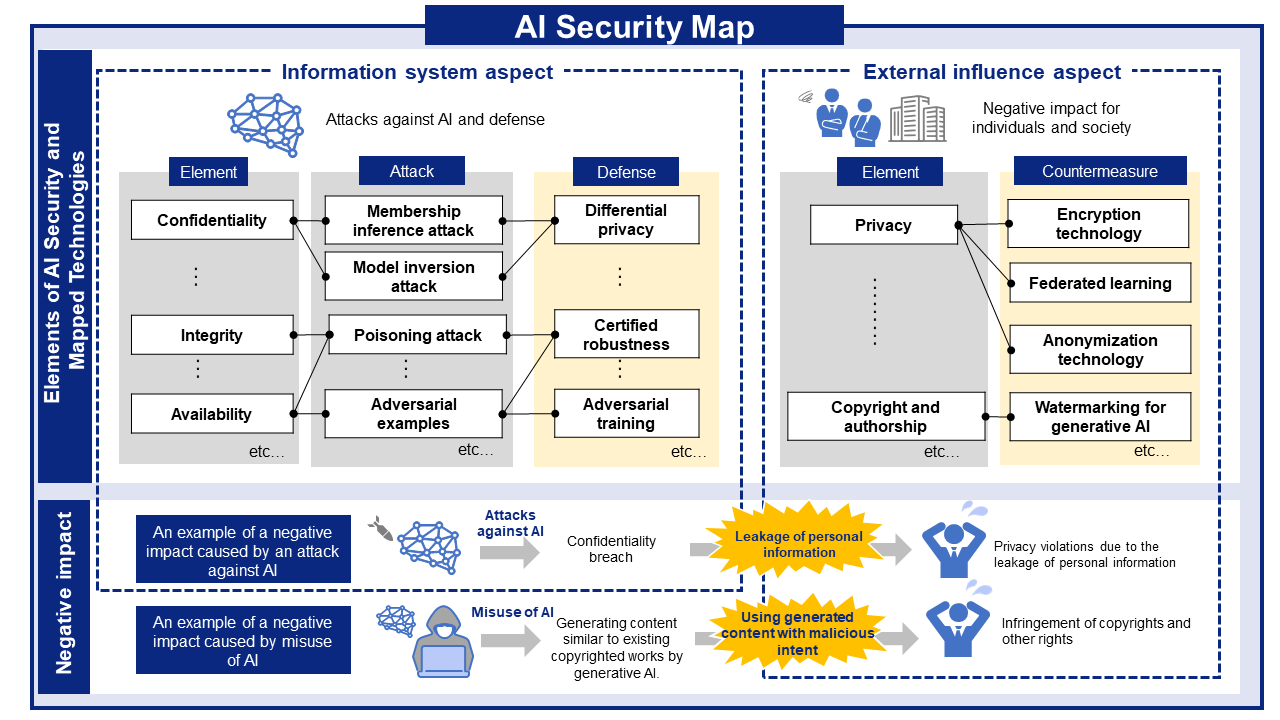
AI SECURITY MAP
AI SECURITY MAP
AI security threats and related mitigations, organized from two perspectives: information Systems and People and Society.